Hadoop是什么
Apache为可靠、可伸缩、分布式计算提供的开源软件。
解决问题:
- 海量数据的存储(HDFS)
- 海量数据的分析(MapReduce)
- 资源管理调度(YARN)
作者:Doug Cutting
受谷歌三篇论文启发(GFS,MapReduce,BigTable)
擅长海量离线日志分析
版本
Apache
官方版本
Cloudera(CDH)
使用下载最多的版本,稳定,有商业支持,在Apache的基础上打上了一些patch。推荐使用。
HDP(Hortonworks Data Platform)
Hortonworks公司发行版本。
伪分布式安装
vmware安装centos虚拟机,内存改大(2G以上),网络适配器选择自定义Vmnet8(NAT)模式。
- NAT:vmvare建立一个虚拟网关,使cetos里的虚拟网卡和windows下的虚拟网卡处于同一网段下(和windows下的物理网卡无关)
centos系统设置虚拟网关
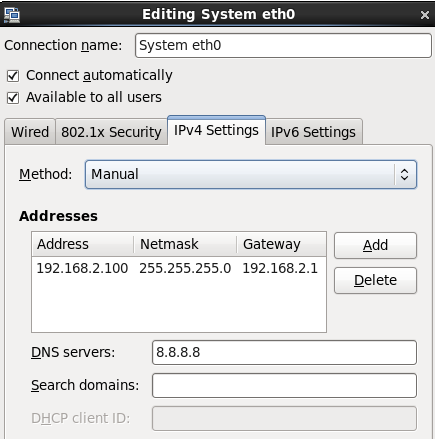
修改完成之后需要重启服务器(reboot)或者重启network服务(sudo service network restart)才可以使用。
windows设置虚拟网关
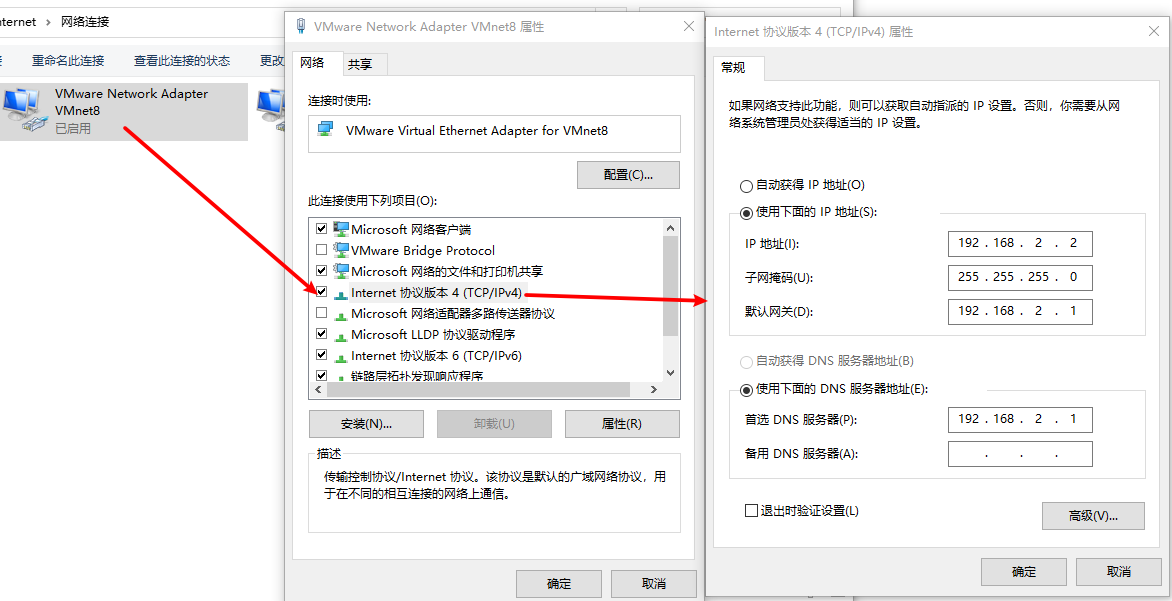
远程连接,
sudo vi /etc/inittab将initdefault的id由5改为3,这样每次启动centos就无需启动图形界面,节约内存;上述操作前需要先将hadoop用户添加到sudoer中才可以有权限:
su进入root;vi /etc/sudoers打开,添加一行hadoop ALL=(ALL) ALL;
HDFS
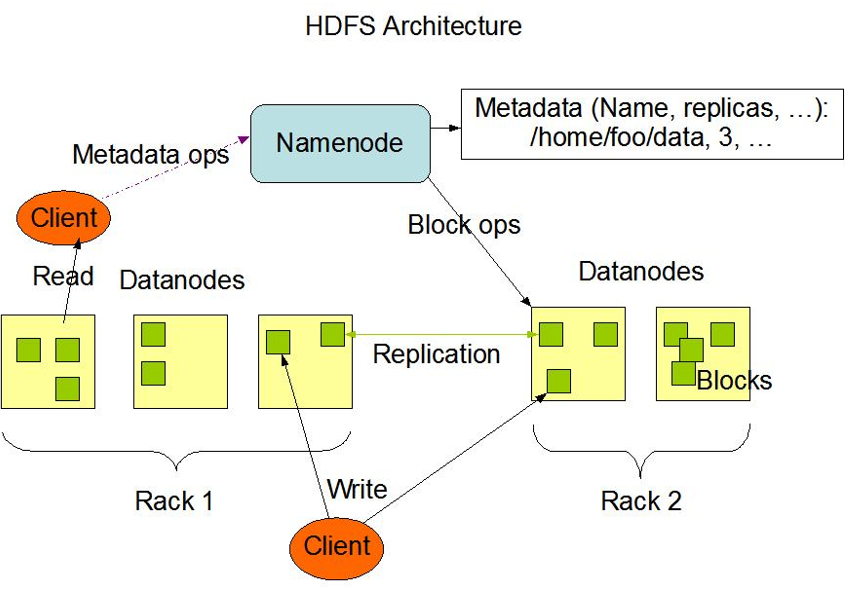
HDFS架构
主从结构
- 主节点, namenode
- 从节点,有很多个: datanode
namenode负责:
- 接收用户操作请求
- 维护文件系统的目录结构
- 管理文件与block之间关系,block与datanode之间关系
datanode负责:
- 存储文件
- 文件被分成block存储在磁盘上
- 为保证数据安全,文件会有多个副本
注:转载文章请注明出处,谢谢~