学习过程主要依照寒小阳系列博客,部分代码由于引用包的问题会有修改,B站也有其Kaggle学习视频,感谢。这里只针对其博客某些地方进行补充。
逻辑回归初步
- 对于某些数据分布,很难从线性模型中找到一个直线能较好的分离开两种数据。而逻辑回归诞生就是为了干这事的,逻辑回归简单来说就等于线性回归乘以sigmoid函数,通过逻辑回归,我们可以将线性回归得到的可能无穷多的值,压缩到0和1的范围内。
从初等数学视角解读逻辑回归
博客中图片全挂,无法阅读,以此代之。(有点复杂……)
逻辑回归应用之Kaggle泰坦尼克之灾
- jupyter实现代码自动补全
- Anaconda Prompt中
python -m pip install jupyter_contrib_nbextensions - Anaconda Prompt中
jupyter contrib nbextension install --user --skip-running-check - 上面两个步骤都没报错后,启动 Jupyter Notebook,上面选项栏会出现 Nbextensions 的选项
- Nbextensions 中勾选 “Table of Contents” 以及 “Hinterland”
- Anaconda Prompt中
- matplotlib.pyplot绘图中文标签无法显示
1 | import matplotlib.pyplot as plt |
- matplotlib画多个子图时重叠
1 | import matplotlib.pyplot as plt |
参数:
Pad:用于设置绘图区边缘与画布边缘的距离大小
w_pad:用于设置绘图区之间的水平距离的大小
H_pad:用于设置绘图区之间的垂直距离的大小
例子:
fig.tight_layout(pad=0.4, w_pad=3.0, h_pad=3.0)
- Matplotlib绘图时x轴标签重叠
1 | fig=plt.figure(figsize=(12,10)) # 设置画布大小 |
- as_matrix() 报警告
FutureWarning: Method .as_matrix will be removed in a future version. Use .values instead, 根据提示:把as_matrix()改为values即可 - 利用Logistic回归算法进行数据建模 ,提示警告
FutureWarning: Default solver will be changed to 'lbfgs'……,解决方法:传入参数后即可消除警告:clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6, solver='liblinear'), LogisticRegerssion算法的solver仅支持以下几个参数’liblinear’, ‘newton-cg’, ‘lbfgs’, ‘sag’, ‘saga’。 - pandas有时因为行数或列数太多显示不全,而用省略号代替
1 | pd.options.display.max_columns = None |
- 关于以下疑问: “以Cabin为例,原本一个属性维度,因为其取值可以是[‘yes’,’no’],而将其平展开为’Cabin_yes’,’Cabin_no’两个属性”,可是直接将cabin作为一个属性,1代表有,0代表无就可以,sex也一样,1代表男,0代表女,为什么非要弄成两个属性呢?
- 答:这样也可以, 不过这里用 dummies 函数自带的功能进行 one-hot 更好,因为后面1,2,3等舱位变成100, 010, 001,如果手动改成0,1,2,数据的范围就不统一了,不利于后面的训练 就 sex 而言, 手动改成0,1完全可以,但也就不符合one-hot编码了
- 在使用其他分类器部分44行
if str.find(big_string, substring) != -1:报错AttributeError: module 'string' has no attribute 'find',这是因为python版本升级,函数名称已有改变,只需要将string改为str即可。 - 在使用其他分类器部分190行
1 | grid_search = GridSearchCV(pipeline, param_grid=param_grid, verbose=3,scoring='accuracy',\ |
报错
1 | TypeError: __init__() got an unexpected keyword argument 'n_iter' |
将报错的全删
1 | cv=StratifiedShuffleSplit(Y_train, test_size=0.2, train_size=None,random_state=seed)).fit(X_train, Y_train) |
但是又有新的错误
1 | TypeError: only integer scalar arrays can be converted to a scalar index |
所以又将代码恢复到了最初,本质在于原sklearn.cross_validation 包中StratifiedShuffleSplit的接口和现在sklearn.model_selection包中StratifiedShuffleSplit的接口不一样,然鹅网格搜索这一部分由于接口很多都改变,导致越改越乱……(先ε=ε=ε=┏(゜ロ゜;)┛,具体可参考以及这里。
- 总结
对于任何的机器学习问题,不要一上来就追求尽善尽美,先用自己会的算法撸一个baseline的model出来,再进行后续的分析步骤,一步步提高。
在问题的结果过程中:
『对数据的认识太重要了!』
『数据中的特殊点/离群点的分析和处理太重要了!』
『特征工程(feature engineering)太重要了!』
『模型融合(model ensemble)太重要了!』
本文中用机器学习解决问题的过程大概如下图所示: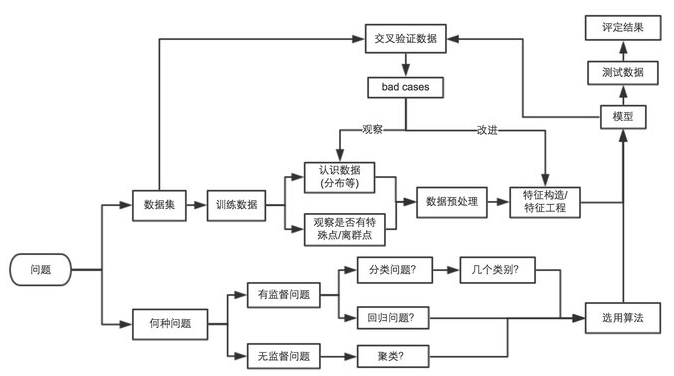
注:转载文章请注明出处,谢谢~