XML语言出现的根本目标在于描述在现实生活中经常出现的有关系的数据。在XML语言中,它允许用户自定义标签。除了用于保存有关系的数据,还经常用作软件配置文件,以描述程序模块之间的关系。
XML内容
文档申明
1
元素
XML元素指的就是XML文件中出现的标签,一个标签分为开始标签和结束标签,格式良好的XML文档必须有且仅有一个根标签,其他标签都是这个根标签的子孙标签。
由于在XML中,空格和换行都作为原始内容被处理,所以,在编写XML文件时,使用换行和缩进等方式让原文件内容清晰可读的习惯可能要被迫改变。
属性
一个标签可以有多个属性,每个属性都有它自己名称和取值,在XML中,标签属性所代表的信息也可以被改成用子元素的形式来描述,例如下面两种写法是一样的:
1
<input name="text">
1
2
3<input>
<name>text</name>
</input>注释
需要注意XML声明之前不能有注释。
CDATA区
在编写XML文件时,有些内容可能不想让解析引擎解析执行,而是当作原始数据处理。在这种情况下,就把这些内容放在CDATA区里,对于CDATA区域里的内容,XML解析程序不会处理,而是直接原封不动的输出。
1
2
3x<![CDATA[
内容
]]>处理指令
处理指令用来指挥解析引擎如何解析XML文档内容,处理指令必须以< ? 开头,以? >作为结尾,XML声明语句是最常见的处理指令。另外,在XML文档中可以使用xml-stylesheet指令通知XML解析引擎,应用css文件显示xml文档内容。
1 |
XML约束
在XML技术里,可以编写一个文档来约束一个XML文档的书写规范,这称之为XML约束。常用的约束技术包括XML DTD和XML Schema
XML DTD
DTD:Document Type Definition,举例:
book.xml
1 | <!DOCTYPE 书架 SYSTEM "book.dtd"> |
book.dtd
1 | <!ELEMENT 书架(书+)> |
查看一份XML文档是否遵循对应的DTD约束,可以使用Eclipse进行校验,DTD文件应该使用UTF-8或者Unicode。
具体DTD的语法在此略过。
XML Schema
XML Schema符合XML语法,也就是说它本身就是一个XML文档,但它扩展名为.xsd,同时,它也必须有一个根节点,名称为chema;
XML Schema对名称空间支持得很好;
XML Schema比DTD支持更多的数据类型,并支持用户自定义新的数据类型;
XML Schema定义约束的能力非常强大,可以对XML实例文档作出细致的语义限制;
XML Schema不能像DTD一样定义实体,比DTD更复杂,但已成为W3C标准,正逐步取代DTD;
编写一个XML Schema约束文档之后,需要把这个文件中声明的元素绑定到一个URI地址上,这个地址,也就是所谓的名称空间,以后XML文件就可以通过这个URL来告诉解析引擎,xml文档中编写的元素来自哪里,被谁约束。
关于名称空间:每个约束模式文档都可以被赋予一个唯一的名称空间,用一个唯一的URI表示。在XML文件中书写标签时,可以通过名称空间声明(xmlns),来声明当前编写的标签来自哪个Schema约束文档。如:
1 | <gsynf:书架 xmlns:gsynf="http://gsynf.github.io"> |
此处使用gsynf来指向声明的名称,方便后面对名称空间的引用。
注意:名称空间的名字语法 很容易让人混淆,尽管以http://开始,那个URL并不指向一个包含模式定义的文件。事实上,这个URL:http ://gsynf.github.io 根本没有指向任何文件,只是一个分配的名字。
为了在一个XML文档中声明它所遵循的Schema文件的具体位置,通常需要在Xml文档中的根节点使用schemaLocation属性来指定,例如:
1 | <gsynf:书架 xmlns:gsynf="http://gsynf.github.io" |
schemaLocation此属性有两个值,第一个值是需要的命名空间,第二个值是供命名空间使用的XML Schema文件位置。
XML编程
所谓XML编程,其实就是CRUD(create,read,update,delete)。
XMl解析方式
DOM:W3C官方推荐的解析方式;
SAX:社区事实上的标准;
XML解析开发包:Jaxp(sun)、Jdom、dom4j
DOM解析
把XML中的节点均变为对象,标签成为Element对象,文本成为Text对象,属性成为Attribute对象,然后根据这些对象之间的关系生成DOM树。DOM解析对增删改查比较容易,DOM解析对内存资源占用较大,不适用于较大的文档对象。
以JAXP为例,
1 | //1.创建解析工厂 |
SAX解析
从上向下读取,读取一行处理一行。所以对内存压力较小,解析速度快,但是只适合读取,不适合增删改查。
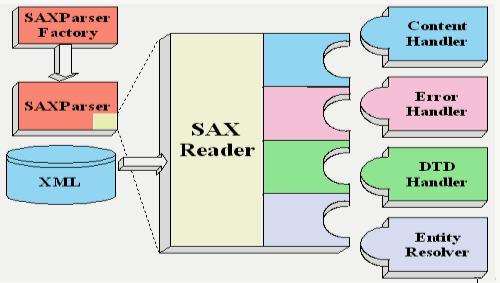
SAX采用事件处理的方式解析XML文档,利用SAX解析文档,涉及两个部分:解析器和事件处理器。
解析器可以使用JAXP的API创建,创建出解析器之后,就可以指定解析器去解析某个XML文档
解析器采用SAX方式在解析某个XML文档时,只要解析到XML文档中的一个组成部分,都会调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会把当前解析到的xml文档内容作为方法的参数传递给事件处理器;
事件处理器由程序员编写,通过事件处理器中方法的参数,就可以轻松得到sax解析器解析到的数据,从而决定如何对数据进行处理。
以JAXP为例,
1 | //1.创建解析工厂 |
除了JAXP,dom4j是一个简单、灵活的开放源代码的第三方库,使用接口和抽象基类,性能优异、功能强大,目前使用最多。
XPath
快速定位需要找到的节点:
如果路径以斜线/开始,表示到一个元素的绝对路径;
如果路径以双斜线//开始,表示选择文档中所有满足双斜线//之后规则的元素(无论层级关系);
星号*表示选择所有由星号之前的路径所定位的元素;
方块中的表达式可以进一步指定元素,其中数字表示元素在选择集里的位置,而last()函数则表示选择集中的最后一个元素;
[@ATT]找到有特定属性的元素,还可以选择属性值[@ATT=‘att’];
……………………………………
1 | /AAA/BBB 找到AAA下的所有BBB |
注:转载文章请注明出处,谢谢~