学习过程主要依照中国MOOC课程,感谢MOOC,感谢北理授课大佬。
文件的使用
文件的类型
-文件是存储在辅助存储器上的数据序列,是数据存储的一种形式。
-文件展现形态:文本文件、二进制文件(本质上,所有文件都是以二进制形式存储)
文本文件
-由单一特定编码组成的文件,如UTF-8编码;
-由于存在编码,也被看作是存储着的长字符串;
-适用于例如:.txt文件、.py文件;
二进制文件
-直接由比特0和1组成,没有统一编码;
-一般存在二进制0和1的组织结构,即文件格式;
-适用于例如:.png文件、.avi文件;
文件的打开和关闭
文件处理步骤:打开-操作-关闭;
文件的打开
< 变量名 > = open(<文件名>,<打开模式>)
1.”r”:只读模式,默认值,文件不存在返回ERROR;
2.”w”:覆盖写模式,文件不存在则创建,存在则完全覆盖;
3.”x”:创建写模式,文件不存在则创建,存在则返回ERROR;
4.”a”:追加写模式,文件不存在则创建,存在则在文件最后追加内容;
5.”b”:以二进制形式打开文件;
6.”t”:以文本形式打开文件,默认值;
7.”+”:与r/w/x/a一同使用,在原功能基础上增加同时读写功能;
文件的关闭
< 变量名 >.close()
文件内容的读取
< f >.read(size=-1):读入全部内容,如果给出参数,读入前size长度;
< f >.readline(size=-1):读入一行内容,如果给出参数,读入该行前size长度;
< f >.readlines(hint=-1):读入文件所有行,以每行为元素形成列表,如果给出参数,读入前hint行;
数据的文件写入
< f >.write(s):向文件写入一个字符串或者字节流;
< f >.writelines(lines):将一个元素全为字符串的列表写入文件;
< f >.seek(offset):改变当前文件操作指针的位置,offse含义如下:0-文件开头,1-当前位置,2-文件结尾;
实例:自动轨迹绘制
根据脚本来绘制图形,不是写代码而是写数据绘制轨迹。
-步骤1:定义数据文件格式(接口);
-步骤2:编写程序,根据文件接口解析参数绘制图形;
-步骤3:编制数据文件;

1 | #AutoTraceDraw.py |
一维数据的格式化和处理
数据组织的维度
一维数据:由对等关系的有序或无序数据组成,采用线性方式组织,对应列表、数组、集合等概念;
二维数据:由多个一维数据组成,是一维数据 的组合形式,对应表格等;
多维数据、高维数据……
一维数据的表示
如果数据间有序:使用列表类型;
如果数据间无序:使用集合类型;
一维数据的存储
方式一:空格分隔;
方式二:逗号分隔;
方式三:其他特殊符号分隔;
一维数据的处理
1 | #从特殊符号分隔的文件中读入数据 |
1 | #采用特殊符号分隔将数据写入文件中 |
二维数据的格式化和处理
二维数据的表示
使用二维列表表示。
使用两层for循环遍历每个元素,第一层遍历每个列表,第二层遍历列表中每个元素。
CSV数据存储格式
CSV:Comma-Separated Values逗号分隔的值
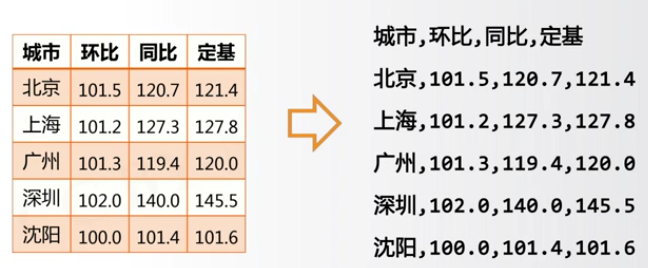
二维数据的存储
一般索引习惯:ls[row][column],先行后列。所以一般按行存储,外层列表每个元素是一行。
二维数据的处理
1 | #从CSV文件中读入数据 |
1 | #从数据写入CSV文件中 |
1 | #遍历每一个元素 |
wordcloud库的使用
简介
-wordcloud库是优秀的词云展示第三方库;
-pip install wordcloud;
-wordcloud库把词云当作一个WordCloud对象,wordcloud.WordCloud()代表一个文本对应的词云;
方法
w.generate(txt):向WordCloud对象w中加载文件txt;
w.to_file(filename):将词云输出为图像文件,.png或.jpg格式;
这里介绍一个有意思的参数mask: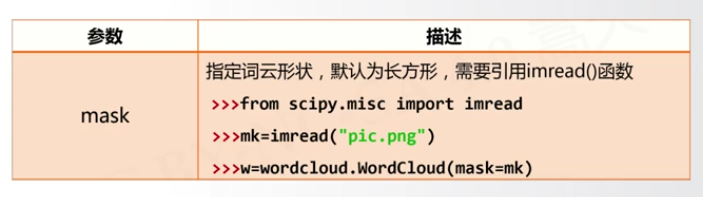
步骤
-步骤一:配置对象参数;
-步骤二:加载词云文本;
-步骤三:输出词云文件;
实例:政府工作报告词云
资源:https://python123.io/resources/pye/新时代中国特色社会主义.txt
资源:https://python123.io/resources/pye/关于实施乡村振兴战略的意见.txt
1 | #常见矩形词云 |
1 | #不规则图形词云 |
注意几个问题:
1、当使用电脑中不存在的字体时,运行程序会报错OSError: cannot open resourse;
2、当不定义参数font_path时,制作中文词云会出现乱码;
3、Linux系统在终端运行:fc-list :lang=zh查看电脑系统所带字体;
以上。
注:转载文章请注明出处,谢谢~