学习过程主要依照中国MOOC课程,感谢MOOC,感谢浙大授课大佬。
这里只讨论内部排序,即默认内存空间足够大,可以存放下所有需要排序的数据。
快速排序
策略:分而治之
步骤:从待排数组中找一个主元pivot,按照比主元大和比主元小将数组分为两个数集再分别递归调用,进行排序。
最好情况:每次选的主元都正好是中分,T(N)=O(N logN)
选主元:方法很多,例如取头中尾三个数的中位数等
适用情况:大规模数据,如果是小规模数据,使用递归可能更费时。
1 | /* 快速排序 - 直接调用库函数 */ |
1 | /* 快速排序 */ |
表排序
表排序是一种间接排序算法,定义一个指针数组作为“表”(table)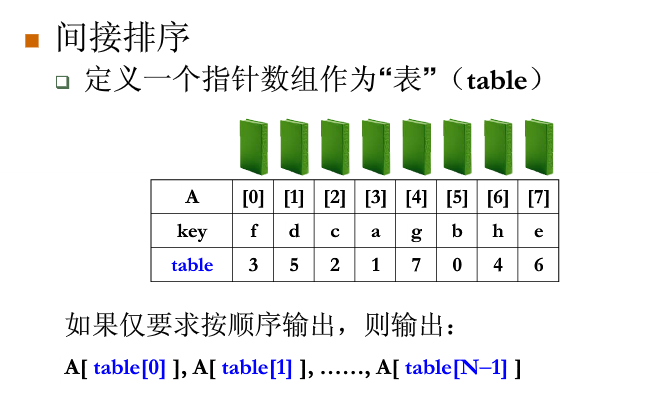
基数排序
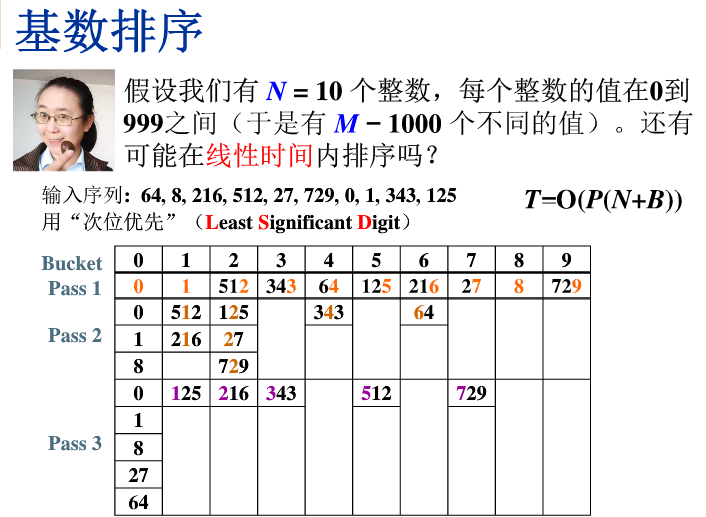
1 | /* 基数排序 - 次位优先 */ |
1 | /* 基数排序 - 主位优先 */ |
排序算法比较
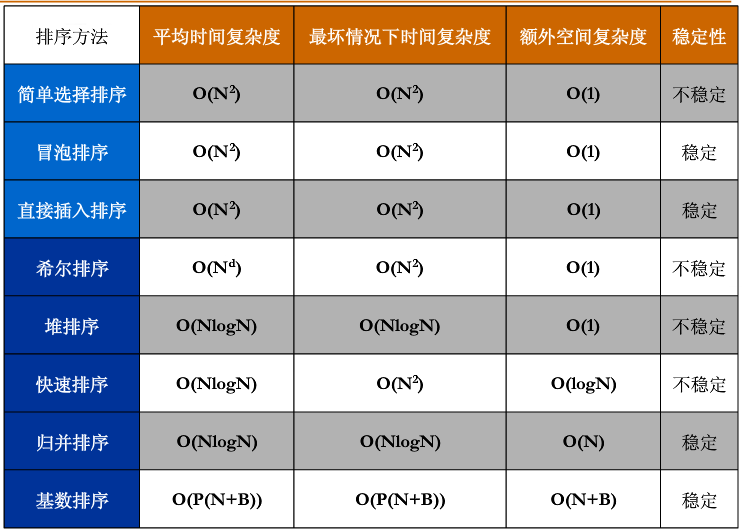
以上。
注:转载文章请注明出处,谢谢~