原文链接:https://arxiv.org/abs/1703.06870
目前找到了非常好的一位博客:https://blog.csdn.net/WZZ18191171661/article/details/79453780, 感谢!
https://blog.csdn.net/jiongnima/article/details/79094159, 这个也不错。
相关知识介绍:
R-CNN-https://www.jianshu.com/p/5056e6143ed5;
Faster R-CNN-https://blog.csdn.net/qq_17448289/article/details/52871461
https://blog.csdn.net/u011974639/article/details/78053203, 个人感觉这两篇讲的很好。
Abstract
- Mask RCNN可以看做是一个通用实例分割架构。
- Mask RCNN以Faster RCNN原型,增加了一个分支用于分割任务。
- Mask RCNN比Faster RCNN速度慢一些,达到了5fps。
- 可用于人的姿态估计等其他任务
1.Introduction
- 实例分割不仅要正确的找到图像中的objects,还要对其精确的分割。所以Instance Segmentation可以看做object dection和semantic segmentation的结合。
- Mask RCNN是Faster RCNN的扩展,对于Faster RCNN的每个Proposal Box都要使用FCN进行语义分割,分割任务与定位、分类任务是同时进行的。
- 引入了RoI Align代替Faster RCNN中的RoI Pooling。因为RoI Pooling并不是按照像素一一对齐的(pixel-to-pixel alignment),也许这对bbox的影响不是很大,但对于mask的精度却有很大影响。使用RoI Align后mask的精度从10%显著提高到50%,第3节将会仔细说明。
- 引入语义分割分支,实现了mask和class预测的关系的解耦,mask分支只做语义分割,类型预测的任务交给另一个分支。这与原本的FCN网络是不同的,原始的FCN在预测mask时还用同时预测mask所属的种类。
- 没有使用什么花哨的方法,Mask RCNN就超过了当时所有的state-of-the-art模型。
- 使用8-GPU的服务器训练了两天。
2.Related Work
- 相比于FCIS,FCIS使用全卷机网络,同时预测物体classes、boxes、masks,速度更快,但是对于重叠物体的分割效果不好。
3.Mask R-CNN
- Mask R-CNN基本结构:与Faster RCNN采用了相同的two-state步骤:首先是找出RPN,然后对RPN找到的每个RoI进行分类、定位、并找到binary mask。这与当时其他先找到mask然后在进行分类的网络是不同的。
- Mask R-CNN的损失函数:L = Lcls + Lbox + Lmask
- Mask的表现形式(Mask Representation):因为没有采用全连接层并且使用了RoIAlign,可以实现输出与输入的像素一一对应。
- RoIAlign:RoIPool的目的是为了从RPN网络确定的ROI中导出较小的特征图(a small feature map,eg 7x7),ROI的大小各不相同,但是RoIPool后都变成了7x7大小。RPN网络会提出若干RoI的坐标以[x,y,w,h]表示,然后输入RoI Pooling,输出7x7大小的特征图供分类和定位使用。问题就出在RoI Pooling的输出大小是7x7上,如果RON网络输出的RoI大小是8*8的,那么无法保证输入像素和输出像素是一一对应,首先他们包含的信息量不同(有的是1对1,有的是1对2),其次他们的坐标无法和输入对应起来(1对2的那个RoI输出像素该对应哪个输入像素的坐标?)。这对分类没什么影响,但是对分割却影响很大。RoIAlign的输出坐标使用插值算法得到,不再量化;每个grid中的值也不再使用max,同样使用差值算法。
- Network Architecture: 为了表述清晰,有两种分类方法
- 使用了不同的backbone:resnet-50,resnet-101,resnext-50,resnext-101;
- 使用了不同的head Architecture:Faster RCNN使用resnet50时,从CONV4导出特征供RPN使用,这种叫做ResNet-50-C4
- 作者使用除了使用上述这些结构外,还使用了一种更加高效的backbone——FPN
3.1.Implementation Details
使用Fast/Faster相同的超参数,同样适用于Mask RCNN
- Training:
1、与之前相同,当IoU与Ground Truth的IoU大于0.5时才会被认为有效的RoI,L{_{mask}}只把有效RoI计算进去。
2、采用image-centric training,图像短边resize到800,每个GPU的mini-batch设置为2,每个图像生成N个RoI,对于C4 backbone的N=64,对于FPN作为backbone的,N=512。作者服务器中使用了8块GPU,所以总的minibatch是16,迭代了160k次,初始lr=0.02,在迭代到120k次时,将lr设定到 lr=0.002,另外学习率的weight_decay=0.0001,momentum = 0.9。如果是resnext,初始lr=0.01,每个GPU的mini-batch是1。
3、RPN的anchors有5种scale,3种ratios。为了方便剥离、如果没有特别指出,则RPN网络是单独训练的且不与Mask R-CNN共享权重。但是在本论文中,RPN和Mask R-CNN使用一个backbone,所以他们的权重是共享的。
(Ablation Experiments 为了方便研究整个网络中哪个部分其的作用到底有多大,需要把各部分剥离开)
- Inference:
在测试时,使用C4 backbone情况下proposal number=300,使用FPN时proposal number=1000。然后在这些proposal上运行bbox预测,接着进行非极大值抑制。mask分支只应用在得分最高的100个proposal上。顺序和train是不同的,但这样做可以提高速度和精度。mask 分支对于每个roi可以预测k个类别,但是我们只要背景和前景两种,所以只用k-th mask,k是根据分类分支得到的类型。然后把k-th mask resize成roi大小,同时使用阈值分割(threshold=0.5)二值化
4.Experiments: Instance Segmentation
4.1.Main Results
在下图中可以明显看出,FCIS的分割结果中都会出现一条竖着的线(systematic artifacts),这线主要出现在物体重的部分,作者认为这是FCIS架构的问题,无法解决的。但是在Mask RCNN中没有出现。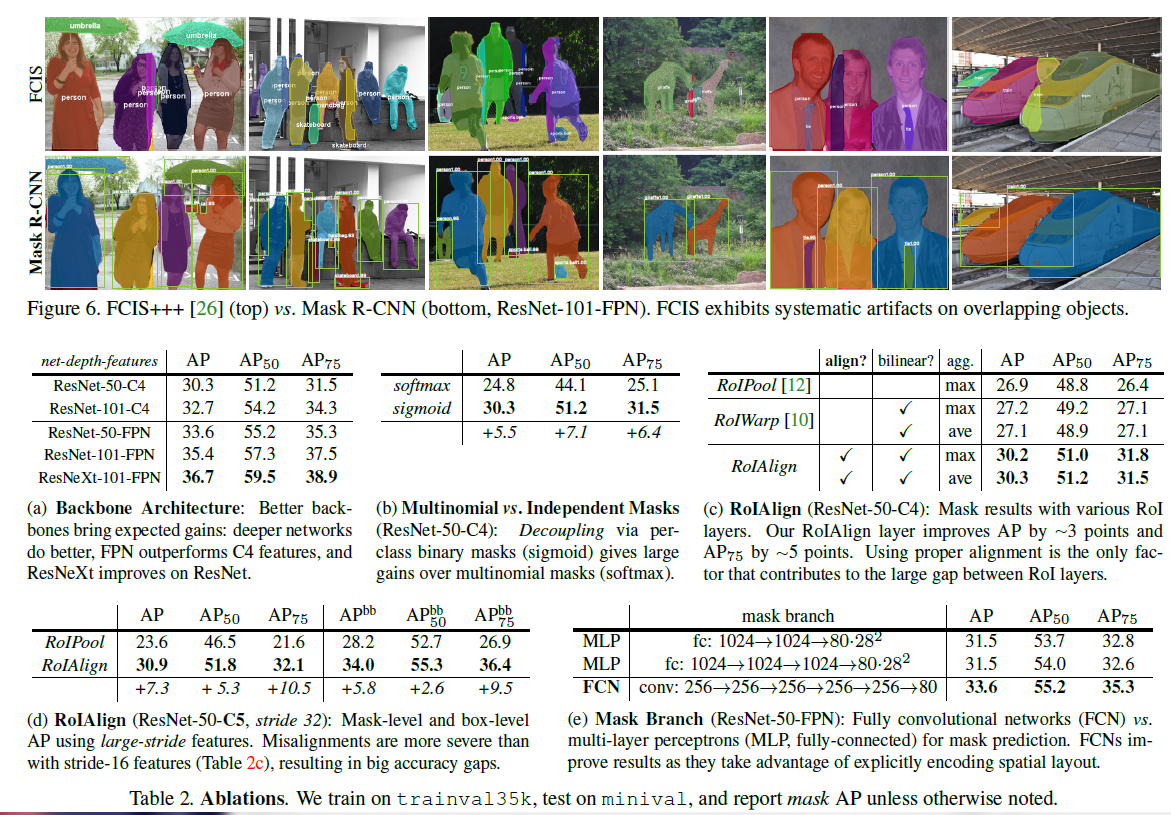
4.2. Ablation Experiments
- Architecture:
从table 2a中看出,Mask RCNN随着增加网络的深度、采用更先进的网络,都可以提高效果。注意:并不是所有的网络都是这样。 - Multinomial vs. Independent Masks:(mask分支是否进行类别预测) 从table 2b中可以看出,使用sigmoid(二分类)和使用softmax(多类别分类)的AP相差很大,证明了分离类别和mask的预测是很有必要的
- Class-Specific vs. Class-Agnostic Masks: 目前使用的mask rcnn都使用class-specific masks,即每个类别都会预测出一个mxm的mask,然后根据类别选取对应的类别的mask。但是使用Class-Agnostic Masks,即分割网络只输出一个mxm的mask,可以取得相似的成绩29.7vs30.3
- RoIAlign: tabel 2c证明了RoIAlign的性能
- Mask Branch:
tabel 2e,FCN比MLP性能更好
4.3.Bounding Box Detection Results
- Mask RCNN精度高于Faster RCNN
- Faster RCNN使用RoI Align的精度更高
- Mask RCNN的分割任务得分与定位任务得分相近,说明Mask RCNN已经缩小了这部分差距。
4.4.Timing
- Inference:195ms一张图片,显卡Nvidia Tesla M40。其实还有速度提升的空间,比如减少proposal的数量等。
- Training:ResNet-50-FPN on COCO trainval35k takes 32 hours in our synchronized 8-GPU implementation (0.72s per 16-image mini-batch),and 44 hours with ResNet-101-FPN。
5. Mask R-CNN for Human Pose Estimation
让Mask R-CNN预测k个masks,每个mask对应一个关键点的类型,比如左肩、右肘,可以理解为one-hot形式。
- 使用cross entropy loss,可以鼓励网络只检测一个关键点;
- ResNet-FPN结构
- 训练了90k次,最开始lr=0.02,在迭代60k次时,lr=0.002,80k次时变为0.0002

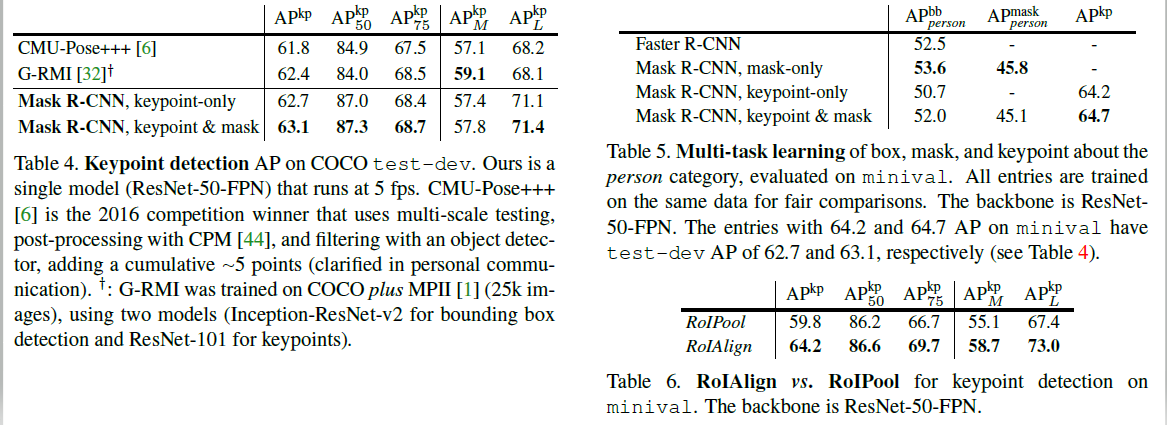
图7.使用Mask R-CNN(ResNet-50-FPN)在COCO测试中的关键点检测结果,以及从相同模型预测的人分割掩码。该模型的关键点AP为63.1,运行速度为5 fps。
以上。
注:转载文章请注明出处,谢谢~